1. Word2Vec 개요
word2vec은 2013년 구글에서 발표한 기법으로 가장 유명한 단어 임베딩 방법이다. 다음의 두가지 논문으로 발표되었다.
- Efficient Estimation of Word Representation in Vector Space(Mikolov et al., 2013a)
- Distributed Representations of Words and Phrase and their Compositionality(Mikolov et al., 2013b)
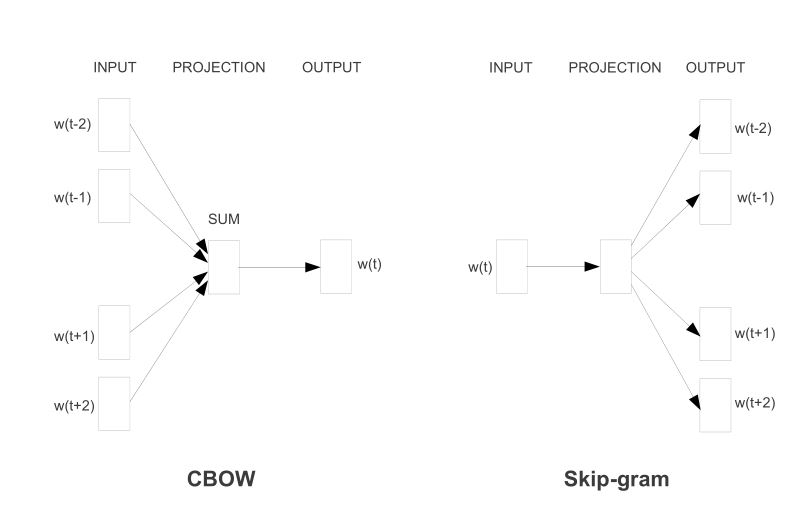
word2vec는 CBOW(Continuous Bags Of Words)와 Skip-gram 두가지 모델이 있는데, CBOW는 주변의 단어들을 가지고 대상 단어를 맞추는 것이고, Skip-gram은 대상 단어를 가지고 주변 단어가 무엇인지를 맞추는 것이다. 단어 임베딩 품질은 CBOW보다 skip-gram이 더 좋은 경우가 많다고 한다.
2. CBOW
CBOW는 주변에 있는 단어들을 가지고 중간에 있는 단어들을 예측하는 방법이다. 예를 들어 "나는 어제 학원에 가서 공부했다" 라는 문장에서 {"나는","어제","가서","공부했다"} 라는 단어로부터 "학원에"를 예측해야 하는 것이다. 이때 예측해야 하는 대상인 "학원에"를 중심단어(Center Word)라고 하고 예측을 위한 주변 단어를 주변단어(Context Word)라고 한다. 중심 단어의 앞, 뒤로 몇개의 단어를 볼 것인지에 대한 범위를 window라고 한다. 즉 window는 주변 단어의 크기 또는 맥락(문맥, Context)크기이다. 앞의 문장 예에서 윈도우가 2이고 예측 단어가 "학원에"라고 한다면 문맥단어는 "나는","어제","가서","공부했다"가 된다. 이 데이터를 만들기 위해서 슬라이딩 윈도우(sliding window)를 활용한다. (다음 그림은 윈도우를 1로 해서 슬라이딩 윈도우로 학습하는 예)

Sliding Window는 학습을 위해서 주변 단어 크기(window)에 따라 말뭉치를 Sliding 하면서 중심 단어의 주변 단어들을 보고 해당 단어들에 대해서 벡터값을 업데이트 하는 방식이라고 할 수 있다. 다음은 중심단어가 "학원에"이고 윈도우가 2인경우 신경망의 입, 출력 구조이다.

입력층의 가중치 행렬은 단어갯수 V와 Projection Layer의 임베딩 차원인 M의 크기의 조합이 된다. (VxM 차원의 행렬) 다음은 상기 예의 입력 x1에 대해서 연산하는 것을 묘사한 그림이다. (v=5, M=3으로 가정)

x1,x2,x3, x4 입력에 대해서 계산된 v1,v2,v3,v4 에 대한 평균값을 구하고 이 평균값에 출력 행렬 Wout 를 곱하면 출력값으로 Score가 나오는데, 이 값을 softmax를 적용해서 확률로 바꿔준다. Wout은 MxV 차원의 행렬이고 Win과 Wout은 서로 아무 관계가 없는 행렬이다. 이 확률값을 가지고 가장 확률이 큰 값으로 정답 레이블을 설정하게 된다.
CBOW에서 중심단어의 확률은 다음과 같이 표시할 수 있다.

즉 주변 2개의 단어가 나타났을 때 해당 단어가 나타날 확률이 되는 것이다.
다음은 Cross-Entroy 오차 식이다. (tk 는 정답 레이블이고 yk는 k번쨰에 해당하는 사건이 일어날 확률)
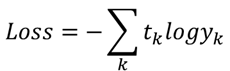
CBOW의 경우 원핫벡터로 구성되어 k번째 해당하는 원소만 1이 되므로 Loss는 다음과 같은 함수가 된다.

따라서 CBOW의 손실함수의 경우 중심단어의 확률에 log를 취해서 -를 붙이면 된다. 이를 "음의 로기 가능도"라고도 한다. 이 함수를 말뭉치 전체로 확장하면 다음과 같다.

CBOW 학습은 이 식이 가능한 작게 만드는 가중치를 찾는 것이다.
입력이 one-hot vector이기 때문에 Win에서 각각의 행이 해당 단어에 대한 분산 표현이 된다. 즉 이 가중치가 단어 분산 표현인 것이다.
3. Skip-Gram 모델
CBOW가 주변단어로 중심단어를 찾는 것이라고 하면, Skip-Gram은 중심단어로 주변단어를 찾는 것이다. Skip-Gram은 입력층은 중심 단어 하나이고, 출력층은 윈도우에 따른 주변 단어(즉, 맥락 단어)갯수이다. 다음은 앞의 예제를 skip-gram으로 나타낸 신경망 구조이다.

입력을 one-hot vector로 만들어 주고, 가중치(Wvxn)을 곱해준다. 이후 출력 가중치(Wnvx)를 곱해주고 softmax를 각각 정용하면 각각의 vector에 대한 확률값이 만들어 진다.
Skip-Gram에서 단어 t로 예측되는 주변 단어의 확률은 다음과 같다.
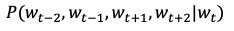
즉 이것은 단어 t가 주어졌을 때 t-2, t-1, t+1, t+2 의 단어가 동시에 존재할 확률을 뜻한다. 주변단어들 사이에 관련성이 없다고 가정하면, 조건부 독립에 따라서 다음과 같이 분리된다.

이를 Cross-Entropy오차 식에 넣으면 다음과 같이 -log에 각각의 확률을 더한게 된다.

Skip-Gram학습은 이 식이 가능한 작게 만드는 가중치를 찾는 것이다.
4. 네거티브 샘플링
Word2Vec의 출력층에서 소프트맥스 함수의 크기는 단어의 수가 많아짐에 따라서 연산량이 크게 증가한다. 수만 단어가 되면 이 연산량은 상당히 무겁게 될 것이다. 이에 다중분류 문제를 이진 분류로 근사하여 연산량을 줄이고자 하는 것이 네거티브 샘플링 기법이 된다.
네거티브 샘플링의 기본 시작은 "다중분류" 모델을 "이진분류"모델로 문제를 근사하는 것이다.
앞의 예에서 보면 CBOW 방식에서 "나는", "어제","가서","공부했다"라는 단어에 대해서 중심 단어가 무엇인가?라는 질문은 다중분류 문제가 된다. 이 것을 "나는", "어제","가서","공부했다"의 중심 단어가 "학원에" 입니까? 라는 질문으로 바꾸게 되는 것이 이진 분류로 바꾸는 것이다. Skip-Gram방식에서는 1)"학원에"라는 중심 단어의 주변 단어가 "나는" 입니까?, 2)"학원에"라는 중심 단어의 주변 단어가 "어제" 입니까? 3)"학원에"라는 중심 단어의 주변 단어가 "가서" 입니까?, 4)"학원에"라는 중심 단어의 주변 단어가 "공부했다" 입니까? 로 질문은 바꾸는 것이다. 즉 이 질문들에 대해서 긍정적이면 1에 가까운 확률을, 부정적이면 0에 가까운 확률을 출력하도록 바꾸는 것이다.
이때 부정적인 질문에 대해서 모든 단어를 학습하는 것은 어렵기 때문에 근사적으로 샘플링을 해서 부정적 단어에 대해서 학습하도록 하는 것이 네거티브 샘플링이 된다.
앞의 예 나는/어제/학원에/가서/공부했다 를 윈도우를 1로 해서 네거티브 샘플링을 적용하는 부분을 생각해 보자. 임베딩 차원은 3으로 하면 Win은 5x3의 행렬이 되고 Wout은 3x5의 행렬이 된다. 다음은 중심단어 "학원에"에 대해서 "어제", "가서" 입력에 대해서 신경망이 Forward 되는 구조이다.

입력의 경우 one-hot vector이기 때문에 가중치 Win의 특정 행의 값으로 바로 표현이 가능하다. "어제","가서"의 두 주변단어에 대해서 해당 행을 더하고 0.5를 곱하면 Projection Layer의 출력이 되고, 여기에 Wout에서 중심 단어의 출력에 해당하는 열을 dot 연산하고 sigmoid 함수를 적용하면 "어제", "가서"라는 주변단어에 대한 "학원에"가 나올 확률을 나타나게 된다.
손실 함수는 역시 Cross-Entroypy Loss를 적용하는데, 이 경우 Sigmoid 출력 y와 정담 레이블 t 에 대해서 다음과 같은 식으로 표현된다.

정답은 긍정=1 또는 부정=0 이기 때문에 t가 1이면 -logy가 손실함수로 출력되고, t가 0 이면 -log(1-y)가 출력된다. 앞의 예에서는 "학원에"에 대한 정답 레이블이 1이기 때문에 손실은 -logy 가 된다.
정답 긍정에 대해서 뿐만 아니라 부정에 대해서도 학습을 해야 하는데, 부정의 경우 긍정보다 계산하는 량이 월등이 많아진다. 따라서 부정의 경우에는 샘플링해서 학습한다. 이것이 "네거티브 샘플링" 의 이름이 붙은 이유이다. 다시 말해서 "네거티브 샘플링" 기법은 긍정적 중심 단어를 학습하고 여기에 부정적 예를 몇개 선별해서 손실을 구하고 이를 최종 손실로 더하여 최종 손실로 계산한다. 이때 긍정은 앞의 Loss함수에 t=1로, 부정은 t=0으로 계산하여 합하면 손실값이 된다. 샘플링의 경우 무작위 샘플링보다는 말뭉치의 통계 데이터를 기준으로 확률분포에 따라서 샘플링 하여 자주 등장하는 단어 중심으로 샘플링 하는 것이 좋다고 한다.



